
Meet Vanna: An Open-Source Retrieval-Augmented Generation Framework for Auto Generating SQL
 |
| Image of Vanna.AI - SQL Generation |
In the dynamic landscape of data-driven applications, efficient and accurate interaction with databases is paramount. Meet Vanna, an open-source Python RAG (Retrieval-Augmented Generation) framework designed for SQL generation and related functionalities. Vanna empowers developers and data professionals to seamlessly generate SQL queries through an innovative and user-friendly approach, utilizing Large Language Models (LLMs) with the Retrieval-Augmented Generation technique. In this comprehensive blog post, we'll delve into the origins, key features, user interfaces, training processes, real-world applications, and the distinct advantages of Vanna.
GitHub | PyPI | Documentation
![]()
![]()
![]()
What is Vanna?
Vanna, an MIT-licensed open-source Python RAG framework, brings an innovative solution to the realm of SQL generation. The framework operates on the principle of Retrieval-Augmented Generation, allowing users to train models on their data and generate SQL queries through straightforward interactions. Let's explore the key components and functionalities that make Vanna stand out.
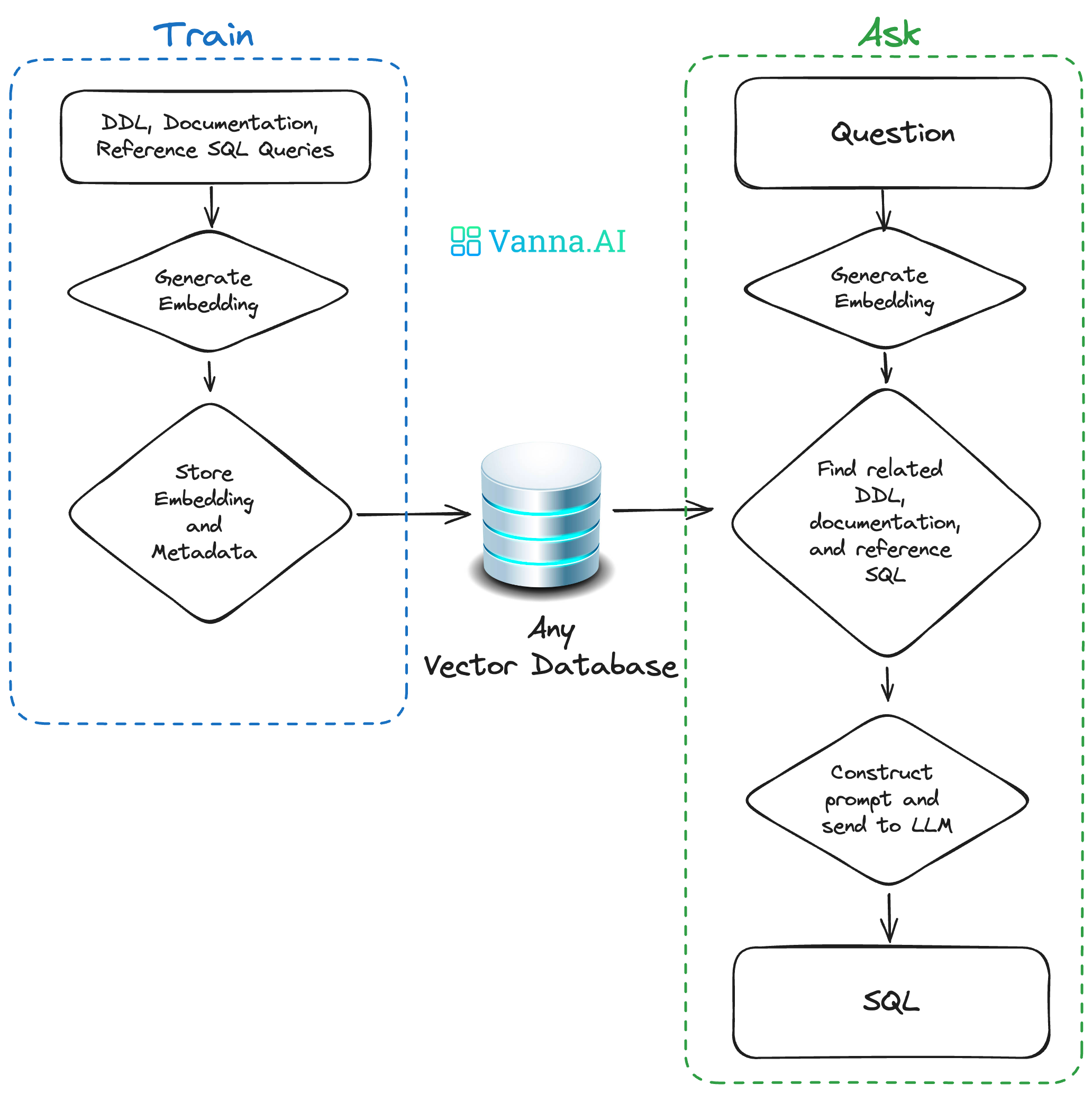
How Vanna Works
Vanna operates in two simple steps: train a RAG "model" on your data and then ask questions that will return SQL queries. The framework simplifies the process of generating SQL queries, making it accessible to both developers and data professionals.
Train a RAG "model" on your data: Vanna provides a user-friendly method to train models on your specific dataset. This step involves storing metadata that will be utilized for subsequent SQL generation.
Ask questions: Once the model is trained, users can interact with Vanna by asking questions related to their dataset. Vanna then returns SQL queries that can be set up to automatically run on the connected database.
User Interfaces
Vanna offers various user interfaces that cater to different preferences and use cases. Whether you prefer working within a Jupyter Notebook or seek a more interactive experience through web apps or Slack, Vanna provides versatile options.
Getting Started with Vanna
To begin using Vanna, refer to the documentation for specifics related to your desired database, LLM (Large Language Model), and more. The documentation provides detailed instructions on installation, importing, training, and asking questions.
Install Vanna
The installation process involves optional packages that can be installed based on your specific requirements. Refer to the documentation for a comprehensive guide.
Import Vanna
Detailed instructions for importing Vanna and customizing the LLM or vector database are available in the documentation.
Training with Vanna
Training a model with Vanna is a crucial step to enhance its accuracy and effectiveness in generating SQL queries. The training process involves different types of statements, such as DDL statements, documentation, and SQL queries.
Train with DDL Statements
DDL statements provide information about table names, columns, data types, and relationships in your database. An example of training with DDL statements is as follows:
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS my-table (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT
)
""")
Train with Documentation
Including documentation about your business terminology or definitions is another way to enrich the training data:
vn.train(documentation="Our business defines XYZ as ...")
Train with SQL Queries
Vanna allows users to add existing SQL queries to the training data, facilitating the generation of new SQL queries based on past examples:
vn.train(sql="SELECT name, age FROM my-table WHERE name = 'John Doe'")
Asking Questions with Vanna
Once the model is trained, users can pose questions to Vanna, and it will generate corresponding SQL queries:
vn.ask("What are the top 10 customers by sales?")
The resulting SQL query might look like:
SELECT c.c_name as customer_name,
sum(l.l_extendedprice * (1 - l.l_discount)) as total_sales
FROM snowflake_sample_data.tpch_sf1.lineitem l join snowflake_sample_data.tpch_sf1.orders o
ON l.l_orderkey = o.o_orderkey join snowflake_sample_data.tpch_sf1.customer c
ON o.o_custkey = c.c_custkey
GROUP BY customer_name
ORDER BY total_sales desc limit 10;
Vanna also provides a table displaying the results and an automated Plotly chart for enhanced visualization.

RAG vs. Fine-Tuning
Vanna incorporates the Retrieval-Augmented Generation technique, which offers distinct advantages compared to fine-tuning:
RAG:
- Portable across LLMs.
- Easy removal of obsolete training data.
- Cost-effective in terms of training and execution.
- More future-proof – can adapt to newer and improved LLMs seamlessly.
Fine-Tuning:
- Ideal for minimizing tokens in the prompt.
- Slow to start and expensive in terms of training and execution.
Why Vanna?
Vanna stands out as a preferred choice for SQL generation due to several compelling reasons:
High Accuracy on Complex Datasets:
- Vanna's capabilities are tied to the training data provided.
- More training data results in better accuracy for large and complex datasets.
Secure and Private:
- Database contents are never sent to the LLM or the vector database.
- SQL execution happens in your local environment.
Self-Learning:
- Allows for "auto-training" on executed queries when using Jupyter.
- Interfaces can prompt users to provide feedback, enhancing future results.
Supports Any SQL Database:
- Connects to any SQL database accessible via Python.
Choose Your Front End:
- Offers flexibility to start in a Jupyter Notebook and extend to various interfaces
like Slackbot, web apps, Streamlit apps, or custom front ends.
Extending Vanna
Vanna's design allows for seamless extension to different databases, LLMs, and vector databases. The VannaBase abstract base class defines basic functionality, and the package provides implementations for OpenAI and ChromaDB. Developers can easily extend Vanna to use their preferred LLM or vector database, as outlined in the documentation.
More Resources
Conclusion
Vanna emerges as a powerful and user-friendly framework for auto-generating SQL queries. Its intuitive training process, versatile user interfaces, and support for various databases make it a valuable asset for developers and data professionals. With a focus on accuracy, security, and adaptability, Vanna represents a significant step forward in simplifying SQL generation. Explore the full potential of Vanna at vanna.ai and contribute to its growing community on GitHub. Enhance your SQL generation experience with Vanna, where accurate and efficient interactions with databases become a reality.









